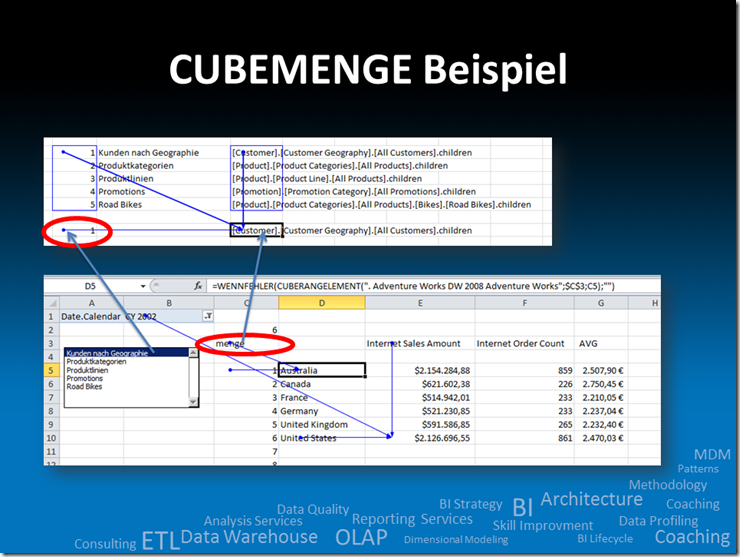
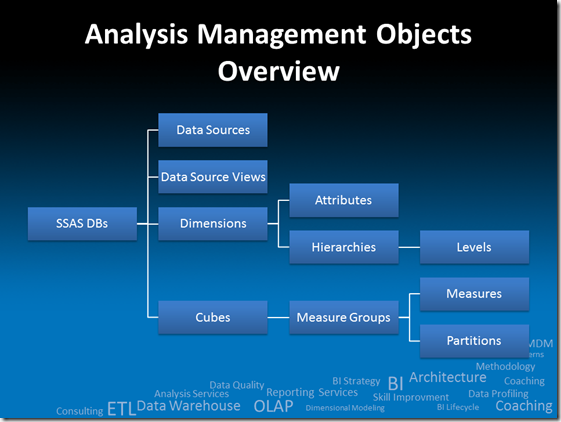
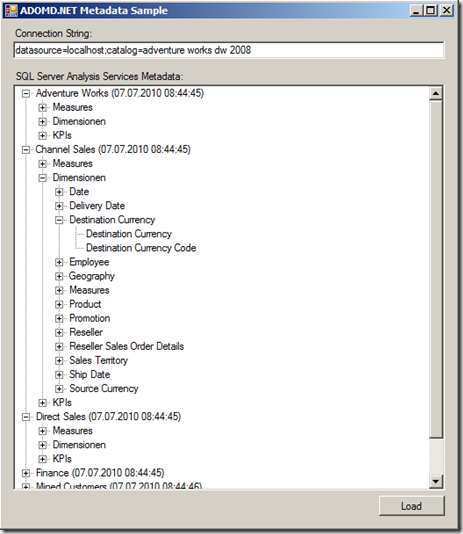
PASS Summit, TechEd & TechNet… was für eine Woche!
Wow, das war doch mal eine Woche! Da gab es endlich wieder etliche Überschneidungen im Kalender. Wir hatten den PASS Summit in Seattle, die TechEd Europe in Berlin und noch ein TechNet MS SQL & BI Seminar in Hamburg. Die Keynotes des Summits gabs auch gleich noch als Livestream. Sessions der TechEd sind wie gewohnt bereits online verfügbar. Sowohl auf dem Summit als auch auf der TechEd wurden diverse Ankündigungen bzgl. des neuen SQL Servers gemacht. Highlights sind wohl u. a.: Project Crescent (ultra cooles Reporting / Dashboard Tool auf Basis Silverlight) Business Intelligence Semantic Model (BISM) VertiPaq in der relationalen Welt (eine Renaissance von ROLAP ?) und vieles, vieles mehr… Und es gab dazu viele Emotionen diese Woche. Chris Webb z. B. sprach da wohl vielen von uns aus der Seele. http://cwebbbi.wordpress.com/2010/11/11/pass-summit-day-2/ Da wurde wohl das eine oder andere ein wenig zu euphorisch angekündigt und präsentiert. Zumindest en...